
It took 955 lines of code—including a custom parser written in PureScript with Markov chain-based heuristics—just to make error messages look nice. Here's why that was worth it.
High-level Goals
Our main goal when rendering stacktraces is to display precisely the information that will help the developer most quickly identify the relevant source code, and attempt to reconstruct a clear picture of the state of execution when the crash occurred. Towards this main goal, we listed several high-level corollaries:
- Details not relevant to debugging the crash should be hidden or minimized, so that relevant details are more apparent.
- Stacktraces should resemble the host language (usually C#), translating arcane low-level representations into something more familiar to the programmer debugging the crash.
- The stacktrace should be stylized with color and typography to increase legibility.
Raw Material
Here is an example of a raw stracktrace reported by the Insights client from a Xamarin app written in C#:
at CoreGraphics.CGContext.set_Handle (IntPtr value) [0x0001b] in /Users/builder/data/lanes/2097/b5396c29/source/maccore/src/CoreGraphics/CGContext.cs:162
at CoreGraphics.CGContext..ctor (IntPtr handle, Boolean owns) [0x00006] in /Users/builder/data/lanes/2097/b5396c29/source/maccore/src/CoreGraphics/CGContext.cs:141
at NGraphics.ApplePlatform.CreateImageCanvas (Size size, Double scale, Boolean transparency) [0x0004a] in /Users/fak/Dropbox/Projects/NGraphics/Platforms/NGraphics.Mac/ApplePlatform.cs:34
at Xamarin.Images.ImageLoader.ImageFromGraphic (NGraphics.Graphic graphic, Nullable`1 maxSize) [0x0007a] in /Users/david/build/confetti/Xamarin.Images/ImageLoader.cs:101
at Xamarin.Images.ImageLoader.LoadImage[T] (T value, Nullable`1 maxSize) [0x00079] in /Users/david/build/confetti/Xamarin.Images/ImageLoader.cs:45
at Confetti.GiftIdeaTableViewCell.GetDefaultGiftImage () [0x0000c] in <filename unknown>:0
at UIKit.UIImageViewExtensions+<LoadImageAsync>c__async0.MoveNext () [0x00206] in /Users/david/build/confetti/UIKit.Extensions/UIImageViewExtensions.cs:42
--- End of stack trace from previous location where exception was thrown ---
at System.Runtime.ExceptionServices.ExceptionDispatchInfo.Throw () [0x0000c] in /Users/builder/data/lanes/2097/b5396c29/source/maccore/_build/Library/Frameworks/Xamarin.iOS.framework/Versions/git/src/mono/external/referencesource/mscorlib/system/runtime/exceptionservices/exceptionservicescommon.cs:143
at System.Runtime.CompilerServices.TaskAwaiter.ThrowForNonSuccess (System.Threading.Tasks.Task task) [0x0003b] in /Users/builder/data/lanes/2097/b5396c29/source/maccore/_build/Library/Frameworks/Xamarin.iOS.framework/Versions/git/src/mono/external/referencesource/mscorlib/system/runtime/compilerservices/TaskAwaiter.cs:199
at System.Runtime.CompilerServices.TaskAwaiter.HandleNonSuccessAndDebuggerNotification (System.Threading.Tasks.Task task) [0x0002e] in /Users/builder/data/lanes/2097/b5396c29/source/maccore/_build/Library/Frameworks/Xamarin.iOS.framework/Versions/git/src/mono/external/referencesource/mscorlib/system/runtime/compilerservices/TaskAwaiter.cs:170
at System.Runtime.CompilerServices.TaskAwaiter.ValidateEnd (System.Threading.Tasks.Task task) [0x0000b] in /Users/builder/data/lanes/2097/b5396c29/source/maccore/_build/Library/Frameworks/Xamarin.iOS.framework/Versions/git/src/mono/external/referencesource/mscorlib/system/runtime/compilerservices/TaskAwaiter.cs:142
at System.Runtime.CompilerServices.TaskAwaiter`1[TResult].GetResult () <0x2b6b50 + 0x00023> in <filename unknown>:0
at Confetti.GiftIdeaTableViewCell+<LayoutSubviews>c__async1.MoveNext () [0x000ea] in /Users/david/build/confetti/Confetti.iOS/Views/GiftIdeaTableViewCell.cs:99
--- End of stack trace from previous location where exception was thrown ---
at System.Runtime.ExceptionServices.ExceptionDispatchInfo.Throw () in /Users/builder/data/lanes/2097/b5396c29/source/maccore/_build/Library/Frameworks/Xamarin.iOS.framework/Versions/git/src/mono/external/referencesource/mscorlib/system/runtime/exceptionservices/exceptionservicescommon.cs:line 143
at System.Runtime.CompilerServices.AsyncMethodBuilderCore.<ThrowAsync>m__0 (System.Object state) in /Users/builder/data/lanes/2097/b5396c29/source/maccore/_build/Library/Frameworks/Xamarin.iOS.framework/Versions/git/src/mono/external/referencesource/mscorlib/system/runtime/compilerservices/AsyncMethodBuilder.cs:line 994
at UIKit.UIKitSynchronizationContext+<Post>c__AnonStorey0.<>m__0 () in /Users/builder/data/lanes/2097/b5396c29/source/maccore/src/UIKit/UIKitSynchronizationContext.cs:line 24
at Foundation.NSAsyncActionDispatcher.Apply () in /Users/builder/data/lanes/2097/b5396c29/source/maccore/src/Foundation/NSAction.cs:line 163
at (wrapper managed-to-native) UIKit.UIApplication:UIApplicationMain (int,string[],intptr,intptr)
at UIKit.UIApplication.Main (System.String[] args, IntPtr principal, IntPtr delegate) in /Users/builder/data/lanes/2097/b5396c29/source/maccore/src/UIKit/UIApplication.cs:line 74
at UIKit.UIApplication.Main (System.String[] args, System.String principalClassName, System.String delegateClassName) in /Users/builder/data/lanes/2097/b5396c29/source/maccore/src/UIKit/UIApplication.cs:line 57
at Confetti.Application.Main (System.String[] args) in /Users/david/build/confetti/Confetti.iOS/Main.cs:line 9
Initial observations:
- Raw stacktraces are plain text, so there's little inherent style to aid legibility.
- Lines are very long due to absolute file paths and qualified type names.
- Hexadecimal addresses (e.g.
[0x0001b]) are likely meaningless for the C# programmer. - Internal runtime artifacts (e.g.
(wrapper managed-to-native)) are likely meaningless for the C# programmer, and not likely to be implicated in the crash. - The lines immediately following
End of stack traceare transformations inserted by the compiler, and not likely to be implicated in the crash. - Generic type notation (e.g.
Class'2[T1,T2]) is not familiar to C# programmers, who use the formClass<T1, T2>. Generic methods exhibit the same notational inconsistency. Furthermore, F#, another .NET language supported for making Xamarin apps, uses yet another representation for generics (e.g.Class<'T1, 'T2'>or evenT1 Class). - The compiler has rewritten async method names as
MoveNexton generated nested classes (e.g.Class.AsyncMethodbecameClass+<AsyncMethod>c__async1.MoveNext). - Nested types use the form
A+B, where a C# programmer expectsA.B. - C#'s builtin type aliases are not always used—the C# developer expects to see
string, notSystem.String. - Constructors are given an unfamiliar name of
.ctorby the compiler. - Types are much harder to read when they are fully qualified, nested, and written with unfamiliar generic notation. Compare a type that a programmer might encounter in their code––
Dictionary<string, Tuple<int, object>>
—to the same type appearing in a stacktrace:
System.Collections.Generic.Dictionary'2[System.String,System.Tuple'2[System.Int32,System.Object]]. Consider further the common case of nested generic collection types and weep.
It became clear that we would lose our minds long before our fragile regular-expression-based rendering pipeline could be extended to address these issues.
Technical Requirements
My designs for how the stacktraces should appear proved divisive because I wanted to aggressively minimize what I considered to be extraneous details in the raw stacktrace, and the engineering team couldn't reach consensus. A sad truth about being a designer is that no matter how well you argue that your design is correct, if an engineer disagrees and produces a working implementation for their preferred design, your argument loses much of its force. I used this sad truth to my advantage this time, offering to implement the stacktrace renderer rather than merely arguing for my technically difficult design. Perhaps this is a small failure as a designer, but nevertheless a victory for the user.
Thankfully, I had a lot of latitude for the implementation. I gathered some high-level 'requirements':
- The Insights front-end is a React application, and stacktrace processing happens on the client, which means that stacktrace processing ultimately needed to be implemented in JavaScript.
- I wanted to use a typed language so that the parser could more reliably evolve over time to address corner cases. Stacktraces can be generated either by the Microsoft .NET runtime or the Mono runtime, introducing subtle inconsistencies that I expected would require ongoing changes to the parser. This ruled out vanilla JavaScript and regular expressions.
- I wanted an especially strong type system because I am not a dedicated engineer on the project and knew my involvement would be sporadic. I wanted to capture as many of my ephemeral expectations about program behavior as I could, and turn those beliefs into explicit claims that the compiler could check.
- I wanted to build a monadic parser so that my overall parser could be composed from smaller, independently testable sub-parsers.
- I wanted to use parser combinators to keep code high-level and readable, mostly for my own benefit as I reengaged with the codebase over time.
Choosing PureScript
These requirements lead me to choose PureScript, "a small strongly typed programming language that compiles to JavaScript," with monad syntax and a fledgling parser combinator library.
Here's some sample PureScript code from the library. fileLocationParser is a purely functional, independently testable parser that parses a FileLocation from a String, first by trying to parse a UNIX-style location, and, if that fails, backtracking and attempting to parse a Windows-style location:
fileLocationParser = try unixFileLocationParser <|> windowsFileLocationParser
unixFileLocationParser = do
file <- untilChar ":"
string ":"
optional $ string "line "
lineNumber <- digits
return $ FileLocation file (readDecimal lineNumber)
windowsFileLocationParser = do
drive <- alpha
string ":"
file <- untilChar ":"
string ":line "
lineNumber <- digits
return $ FileLocation (drive <> ":" <> file) (readDecimal lineNumber)
I hope you can see that monadic parsing with combinators is more modular and maintainable than regular expressions, and high-level enough so that most programmers can understand what's happening.
Transformations
Since the parser builds an abstract syntax tree of the stacktrace, it's straightforward to apply transformations to this tree before it's rendered. Some of the transformations we apply:
- Collapse recursive stack cycles, which are prevalent in UI layout code.
- Collapse compiler-inserted frames.
- Alias built-in types (e.g
System.Boolean→bool). - Rewrite compiler-generated async methods names to more closely resemble names the programmer would recognize.
For example, here's a transformation that uses pattern matching to rewrite async invocations:
-- If an invocation is a lifted async, rewrite its method and drop the compiler genereted child class
unliftAwait :: Invocation -> Maybe { invoke :: Invocation, awaitN :: Int }
unliftAwait (Invocation typ meth) = do
info <- unlift typ
let meth' = method info.methodName Nil
let invoke' = Invocation info.newType meth'
return { invoke: invoke', awaitN: info.awaitN }
where
unlift :: Type -> Maybe { newType :: Type, methodName :: String, awaitN :: Int }
unlift
(Type t@{
child: Just
(Type {
child: Nothing,
name: LiftedAsync methodName awaitN
})
}) = Just { newType: Type (t { child = Nothing }), methodName: methodName, awaitN: awaitN }
unlift (Type t@{ child: Just child }) = do
info <- unlift child
let t' = t { child = Just info.newType }
return $ info { newType = Type t' }
unlift _ = Nothing
The Result
The entire library, including parsing, transformation passes, and HTML/JSON output is 955 lines with an average line length of 34 characters. It's a delight to maintain and deploys as a single JavaScript file.
Here's the result of parsing and rendering the sample stacktrace mentioned earlier:
Note that,
- Compiler-generated async machinery is folded.
- Almost all types hide their namespaces, but are shown on hover.
- Filenames hide their directories, but are shown on hover.
- Transformations are applied to alias built-in type names (e.g.
string) and rewrite compiler-generated async methods to more closely resemble names the programmer would recognize.
And here's a screenshot of how stacktraces appear in the product:
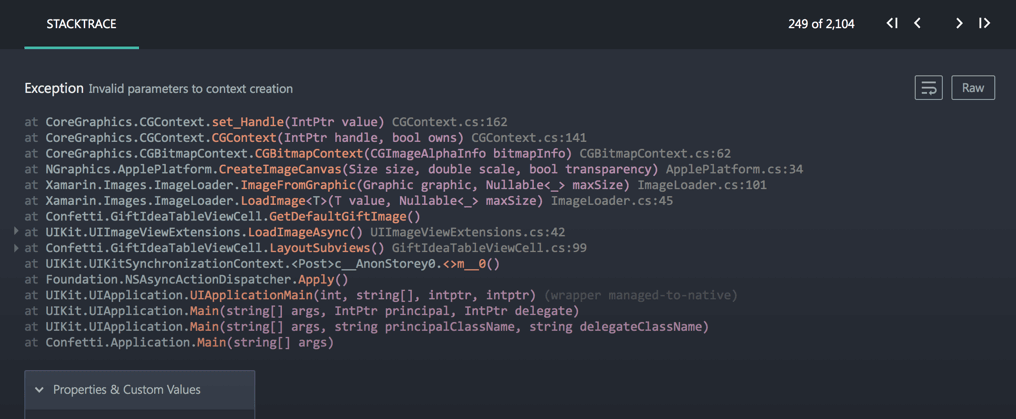
Like I said, a hell of a lot of technology behind a deceptively simple design!
Final Considerations and Future Work
The monadic code performs adequately but is still much slower than a hand-built JavaScript parser should be, often taking over 50ms to parse a large stacktrace. I expect future generations of the PureScript compiler to improve this.
In the future, I'd like to design responsive stacktraces, that hide or show more or less information depending on viewport width.